The history of software architectures is a history of the ebb and flow of centralization and distribution. Centralization requires good network connections while promising simplicity, homogeneity, and ease of management. Distribution offers robustness and potentially unbounded scalability, but has high demands on design, especially in terms of security.
Currently, the discussion is on sensor devices and the Cloud. Sensors measure the environment, people, movement, temperature, any of a million potential attributes of the world around us. Vehicles, drones, smart buildings, our mobile phones – they all collect vast amounts of data on their surroundings. Centralizing the sensor data on the Cloud offers a simple, manageable and immensely powerful data platform, making it easy to analyse the data, make decisions based on the analysis, and act upon the decisions. However, such a vertical solution introduces potentially high latencies due to the physical distance and possibly numerous network hops between the sensor arrays and the Cloud platform. Further, transmitting the data may require a lot of bandwidth while draining the batteries of wireless devices.
The figure below shows a simplified view of the vertical, Cloud based sensor data architecture. Data is collected at the end devices, with a white background, but aggregated and processed at the central Cloud.
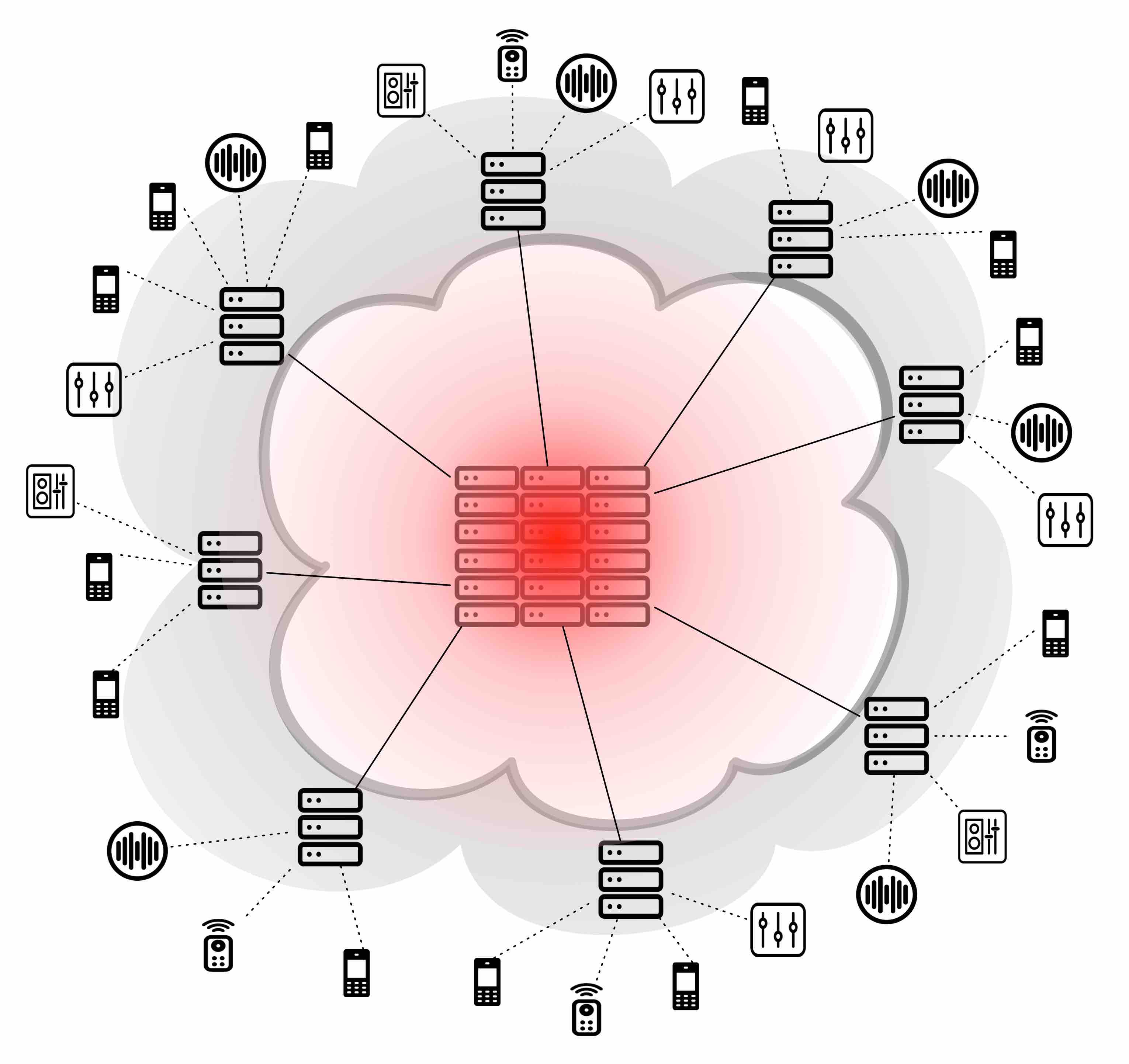
A natural focal point in the discourse are the network infrastructure devices between the wireless and the wired networks, aptly named the “Edge”: gateways, routers, access points. Wireless connections, while making it easy to deploy sensors en masse, do not offer the same reliability and transmission capacity as cables. Three broad use cases in particular suffer from a vertical sensor-to-cloud architecture:
- Applications requiring low latencies (e.g. autonomous vehicles).
- Applications producing vast amounts of data (e.g. industrial control systems)
- Applications in heavily regulated areas, especially in terms of privacy (e.g. personal health monitoring)
Edge Computing (EC) tries to solve the data centralization problems by – distribution. Shreds of the Cloud are dragged to the Edge, introducing computing and storage resources in close proximity to where the data is produced. The figure below shows a simplified view of the Edge computing architecture. Data is collected at the sensor devices, but processed both at the Edge (on grey) as well as in the Cloud.
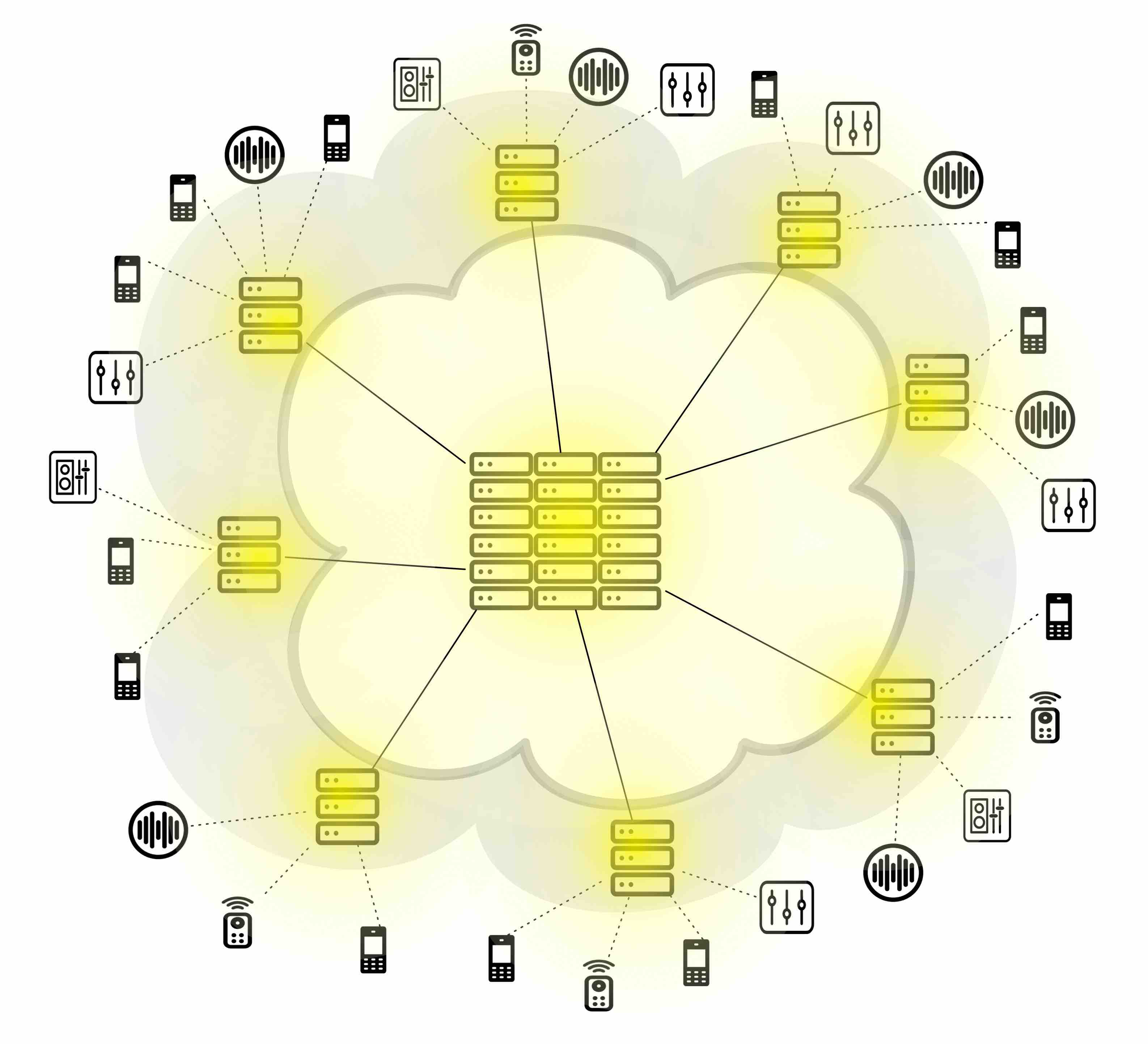
The EC architecture, illustrated above, has largely been drafted by network infrastructure providers. These providers are aiming, among other things, to increase the value of their offering. Making network infrastructure devices smarter by allowing their computing resources be used by the applications is an obvious way of increasing their value.
However, while improving on the vertical model, the architecture still has some limitations. While greatly reducing the latencies, EC still forces a data round trip: raw data from the sensor devices to the Edge for analysis, back with the results and control messages. Further, the network topology necessarily seeps to the application level, requiring the application developer to understand the Edge host’s in-between position.
Yet another architecture, often referred to as the “Ad-hoc Cloud”, attempts to address these issues. Illustrated below, the Ad-hoc Cloud takes advantage of all available computing resources, aggregating computational resources from both the nearby end devices, the Edge, and the Cloud. Thus, the architecture decouples the network topology from the application execution, allowing computational upload decisions to be made based on a cost/benefit calculation of the resources and transmission channels available.

Further reading:
- Mach, P., & Becvar, Z. (2017). Mobile Edge Computing: A Survey on Architecture and Computation Offloading, 19(3), 1628–1656. https://doi.org/10.1109/COMST.2017.2682318
- Mao, Y., You, C., Zhang, J., Huang, K., & Letaief, K. B. (2017). A Survey on Mobile Edge Computing: The Communication Perspective, 19(4), 2322–2358. https://doi.org/10.1109/COMST.2017.2745201